
אחרי 12 שנים שאני מטפל באתרים גדולים, אני יכול להגיד לכם דבר אחד בוודאות: ב-80% מהמקרים שבהם לקוח מתלונן ש"גוגל לא מאנדקס את הדפים החדשים שלי," הבעיה היא לא שגוגל לא רואה אותם. הבעיה היא שגוגל עסוק בלסרוק 14,000 וריאציות URL של דף קטגוריה אחד עם פילטרים, במקום לגעת בדף המוצר החדש שהעליתם אתמול.
זה Crawl Budget. וזה לא נושא רק לאתרי ענק.
- גם אתר "קטן" עם 400 מוצרים יכול להיראות לגוגלבוט כאתר של 180,000 דפים בגלל פילטרים ופרמטרים
- noindex לא חוסך תקציב סריקה — רק robots.txt עוצר סריקה בפועל
- ניתוח לוגי שרת הוא הכלי האמיתי היחיד לאבחון בעיות Crawl Budget
- מהירות שרת היא הגורם המשפיע ביותר על כמות הסריקה שגוגל מקצה לאתר
- שלושה שלבים: מיפוי, ניקוי, ניטור — זו עבודה שוטפת ולא פרויקט חד-פעמי
הטעות הכי יקרה שאני רואה: לחשוב ש-Crawl Budget זה בעיה של אתרים עם מיליון דפים
בואו נשים את זה על השולחן. גוגל עצמם כתבו שאתרים מתחת ל-1,000 דפים בדרך כלל לא צריכים להתעסק עם זה. ואז אני נכנס לאתר WooCommerce עם 400 מוצרים, מסתכל ב-Search Console, ורואה שגוגלבוט סורק 180,000 כתובות URL בחודש. איך זה אפשרי? פילטרים. פרמטרים. תגיות. דפי חיפוש פנימי שלא חסומים. כל אלה מנפחים את האתר שלכם בעיני הבוט פי 400, גם אם בעיניכם יש שם 400 דפים.
אז כן, גם אתר "קטן" יכול להיראות לגוגלבוט כמו אתר של ענק. ההבדל היחיד הוא שאתם לא יודעים על זה, ולכן אתם לא מטפלים בזה. ממליץ לקרוא את המדריך הרשמי של גוגל לניהול תקציב סריקה כדי להבין את שני המרכיבים שמרכיבים אותו: Crawl Capacity Limit (כמה השרת שלכם מסוגל להחזיק) ו-Crawl Demand (כמה גוגל בכלל רוצה לסרוק אתכם).
מה ההבדל בין Crawlability, Crawl Budget ו-Indexing? (ולמה זה לא ניואנס סמנטי)
הרבה אנשי SEO מבלבלים בין שלושת המושגים האלה. וזו לא בעיה תיאורטית. הבלבול הזה הוא הסיבה שאנשים שמים noindex על דף, מוסיפים לו Disallow ב-robots.txt, ואז מתפלאים שהדף עדיין מופיע בגוגל. תאמינו לי, עשיתי את הטעות הזאת בעצמי בשנים הראשונות שלי בתחום.
הסדר חשוב. דף קודם נסרק (Crawl), אחר כך גוגל מחליט אם לאנדקס אותו (Index), ואז יש לו סיכוי להופיע בתוצאות. אם תחסמו את הסריקה, גוגל אף פעם לא יראה את ה-noindex שהטמעתם. הוא יראה רק את הקישורים החיצוניים שמצביעים אליו, וייתכן שיציג את ה-URL בתוצאות בלי כותרת ובלי תיאור. מביך.
למה הקטגוריות שלכם נסרקות 50 פעם בשבוע והבלוג שלכם פעם בחודש?
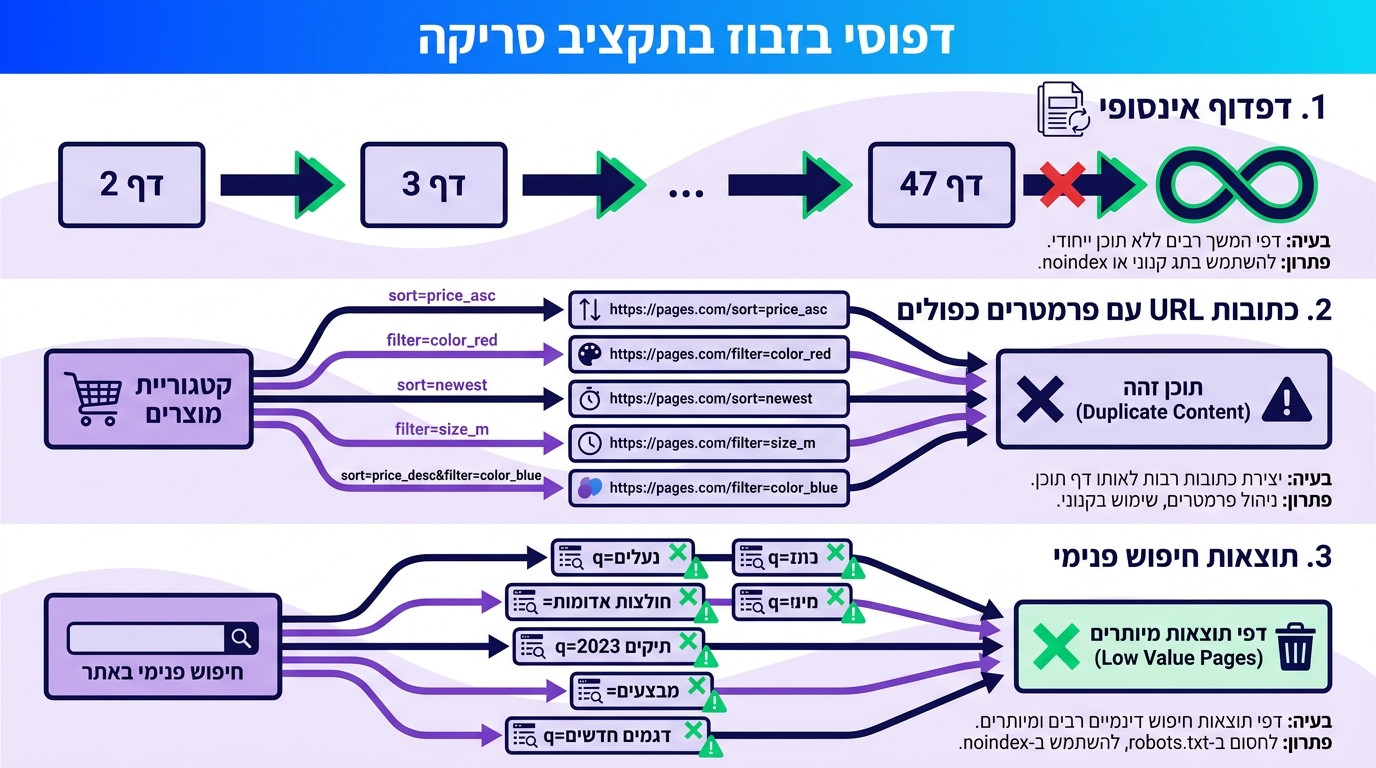
זה אחד התרחישים שאני רואה כמעט בכל חשבון חדש שנכנס אלינו. בעל אתר מתלונן: "השקעתי 8,000 שקל על מאמר עומק, הוא באתר כבר חודשיים, וגוגל בקושי מסתכל עליו." בודק את לוגי השרת, ומה אני מוצא? גוגלבוט סורק את /category/products/?sort=price&color=blue&size=large שלוש פעמים ביום. את המאמר? פעמיים בחודש.
הסיבה פשוטה. גוגל מקצה תקציב סריקה לפי איך שהוא מבין את מבנה האתר שלכם. אם רוב הקישורים הפנימיים מובילים לדפי קטגוריה עם פרמטרים, הוא מסיק שזה הדבר החשוב. אם המאמר שלכם קבור בעמוד 4 של ארכיון הבלוג, בלי קישור פנימי מדף בית או מדף קטגוריה ראשי, הוא נחשב פחות חשוב. השוואת מערכות קידום אתרים יכולה לעזור לכם להבין איך כלים אוטומטיים מזהים את הבעיות האלה לפני שהן הופכות לקריטיות.
שלושה דפוסים של "בזבוז סריקה" שאני מוצא ב-90% מהאתרים
פאגינציה אינסופית. דפי /page/2, /page/3, עד /page/47, כאשר כל דף מכיל סניפטים של אותם מאמרים. גוגלבוט סורק את כולם.
פרמטרים שכפולים. אותו דף קטגוריה מופיע ב-?sort=price, ?sort=name, ?orderby=date, וכל אחד נסרק כדף נפרד.
חיפוש פנימי פתוח לאינדוקס. מישהו חיפש "מתנה לסבתא" באתר שלכם, נוצר URL כמו /?s=מתנה-לסבתא, גוגל מצא אליו קישור איפשהו, ופתאום יש לכם 3,000 דפי חיפוש פנימי בסריקה.
איך באמת יודעים שיש בעיית Crawl Budget? (לא לפי הרגשה)
אני לא סומך על "ההרגשה" של אף אחד בנושא הזה. כולל שלי. הדרך היחידה לדעת היא להסתכל בנתונים. יש שלושה מקומות שאני בודק לפי הסדר הזה:
קודם כל, דוח Crawl Stats ב-Search Console. שם רואים סך הבקשות ביום, זמן תגובה ממוצע, חלוקה לפי קודי תגובה, ולפי סוג קובץ. אם 40% מהבקשות מגיעות עם 404, יש לכם בעיה. אם זמן התגובה מעל 1,000ms בממוצע, יש לכם בעיה אחרת. התיעוד הרשמי של דוח Crawl Stats מסביר בדיוק איך לקרוא כל מדד, כולל איך שרשרת הפניות נחשבת כמה בקשות נפרדות.
שנית, URL Inspection Tool לדפים ספציפיים שלא מתאנדקסים. אם הדף בסטטוס "Discovered – currently not indexed," זו אינדיקציה ברורה ש-Crawl Budget לא הגיע אליו.
שלישית, וזה הכלי הכי חשוב, ניתוח לוגי שרת. רק שם רואים את האמת המלאה: אילו URL נסרקו, מתי, על ידי איזה בוט, וכמה פעמים. הדוחות של גוגל הם דגימה. הלוגים הם האמת. לוח בקרה לקידום אתרים WEBFORCE מאחד את שלוש שכבות המידע האלה למקום אחד, כך שאני לא צריך לעבור בין ארבעה כלים כדי להבין מה קורה.
ניתוח לוגי שרת: הכלי שכולם מדברים עליו וכמעט אף אחד לא משתמש בו
בואו אהיה כן. רוב אנשי ה-SEO בארץ לא יודעים להסתכל בלוגים. וזה בסדר, זה לא טריוויאלי. אבל זה גם הסיבה שהם מפספסים את ה-80% מהבעיות. גוגל עצמם ממליצים לבדוק access logs כדי להבין דפוסי סריקה. הם לא ממליצים על זה סתם.
מה אני מחפש בלוגים? קודם כל, אני מסנן רק את הבקשות של Googlebot (User-Agent + אימות IP, כי יש הרבה בוטים שמתחזים). אחר כך אני בונה טבלת תדירויות: איזה URL נסרק הכי הרבה, איזה הכי פחות. כמעט תמיד מוצא משהו שגורם לי לעצור ולומר "רגע, למה הדבר הזה נסרק 800 פעם החודש?"
האם noindex חוסך Crawl Budget? (התשובה תפתיע אתכם)

לא. ובגדול לא.
זו אחת התפיסות השגויות הכי נפוצות בתעשייה. מישהו קורא איפשהו ש-noindex "מסיר דפים," ומסיק שזה גם חוסם סריקה. שגיאה. כדי שגוגלבוט יראה את התג noindex, הוא חייב לסרוק את הדף קודם. כל דף עם noindex נסרק לפחות פעם, ובהמשך נסרק שוב ושוב כדי לוודא שהתג עדיין שם.
אז מה כן? הדוקומנטציה הרשמית של גוגל על noindex מסבירה שהוא כלי לניהול אינדוקס, לא לניהול סריקה. הוא אומר לגוגל "סרוק את זה, אבל אל תציג בתוצאות." בטווח ארוך, דפים עם noindex אכן נסרקים פחות בתדירות, אבל זה אפקט עקיף, לא ישיר.
נתקלתי בזה אצל לקוח גדול לפני שנה: 12,000 דפי "לא להציג" שהמשיכו להופיע בתוצאות חיפוש למשך שנתיים. הנזק התדמיתי והעסקי היה משמעותי.
- noindex = "סרוק, אבל אל תציג בתוצאות" (לא חוסך סריקה)
- Disallow ב-robots.txt = "אל תסרוק בכלל" (חוסך סריקה אבל לא מונע אינדוקס)
- שילוב שניהם = מתכון לאסון
robots.txt: הכלי שחוסך הכי הרבה Crawl Budget (ויכול גם להרוס לכם את האתר)
robots.txt הוא הדרך היחידה האמיתית לעצור סריקה. המדריך של גוגל ל-robots.txt ברור לחלוטין בנקודה הזאת. אבל אם תשתמשו בו לא נכון, תורידו לעצמכם דפים חשובים מהאינדקס, וזה יכול לקחת חודשים לתקן.
מה כדאי לחסום ב-robots.txt?
- סביבות staging ופיתוח
- דפי login ואזורי ניהול
- תוצאות חיפוש פנימיות
- פרמטרים שיוצרים כפילויות (sort, orderby)
- וריאציות פילטר שאין להן ערך עצמאי
מה אסור לחסום?
- כל דף שאתם רוצים שיהיה בגוגל, גם אם זמני
- קבצי CSS ו-JS שגוגל צריך כדי לרנדר את הדף
- תמונות ומשאבים ויזואליים חשובים
robots.txt חוסך Crawl Budget רק כשהוא חוסם את הדברים הנכונים. כשהוא חוסם את הדברים הלא נכונים, הוא לא חוסך תקציב — הוא פשוט מוחק לכם את האתר מגוגל.
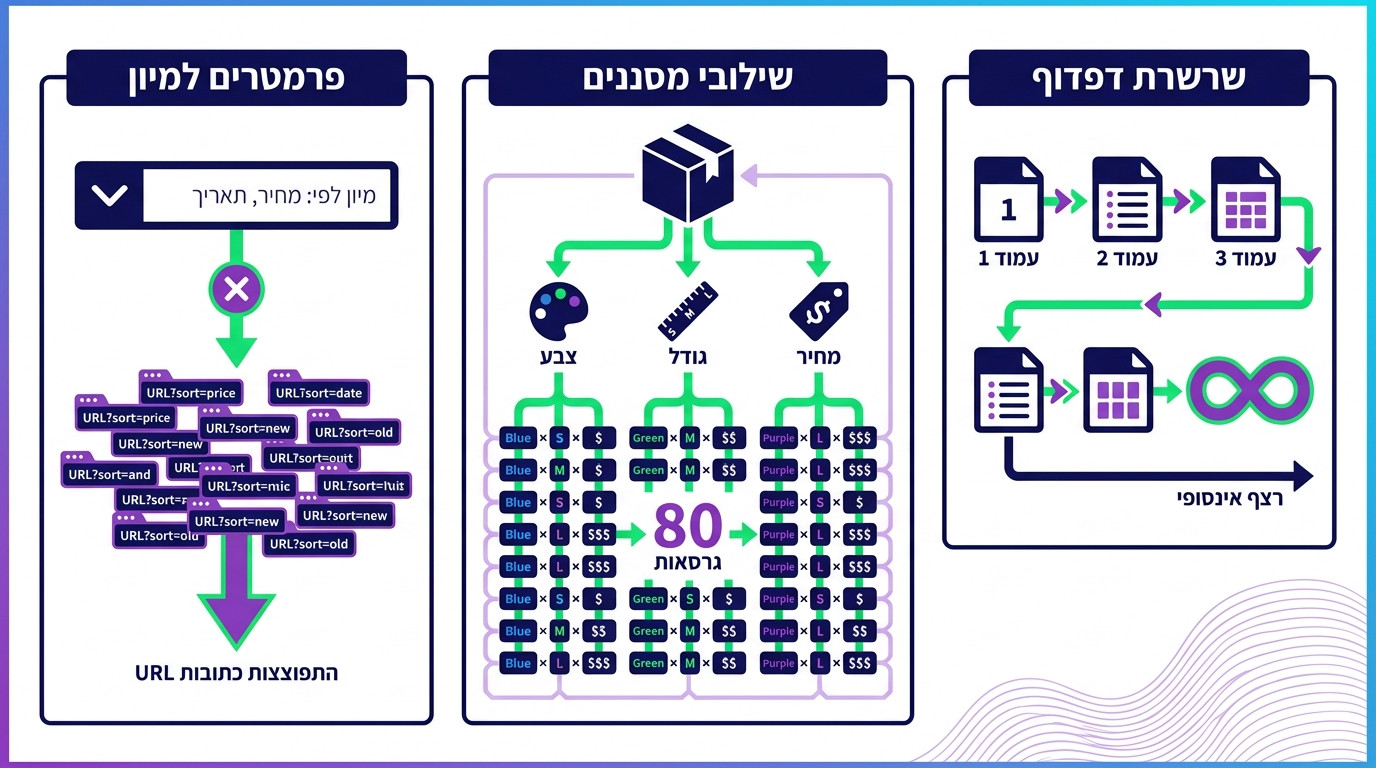
פרמטרים, פילטרים ופאגינציה: שלושת הרוצחים השקטים של תקציב סריקה
אני אתן לכם דוגמה מהשבוע. לקוח חדש, אתר eCommerce עם 1,200 מוצרים. בדקנו את ה-Crawl Stats: גוגל סורק 95,000 כתובות URL בחודש. איך 1,200 הופך ל-95,000? כל מוצר קיים בכ-80 וריאציות בגלל פילטרים: צבע, מידה, סוג, מחיר, מיון. גוגל ראה את כל הקומבינציות כדפים נפרדים.
המסמך החדש של גוגל על Faceted Navigation נותן מסגרת ברורה לטיפול במצב הזה. הגישה שלי, אחרי שעשיתי את זה עשרות פעמים:
פרמטרים של מיון (sort, orderby): Disallow ב-robots.txt. אין סיבה שיהיו באינדקס.
פרמטרים של פילטרים פופולריים (צבע, מידה): canonical לדף הקטגוריה הראשי, אבל לתת לגוגל לסרוק חלק מהם כדי שיבין את המבנה.
פרמטרים של מעקב (utm_source, fbclid): canonical לגרסה הנקייה, אופציונלית גם Disallow.
פאגינציה: לתת לסרוק, אבל לוודא שכל דף מציג תוכן ייחודי. לכלול ב-sitemap רק את עמוד 1 של כל קטגוריה.
מהירות שרת: למה זה הגורם הכי חשוב ל-Crawl Budget (ואף אחד לא מדבר עליו)
גוגל לא רוצה להפיל לכם את האתר. אם השרת מגיב לאט, אם יש 500 שגיאות, אם הזמינות מתחת ל-99%, גוגל מקטין את ה-Crawl Capacity באופן אוטומטי. הוא אומר לעצמו: "האתר הזה לא יכול להחזיק יותר, אני אסרוק פחות." וכך אתם נכנסים למעגל קסמים: שרת איטי, פחות סריקה, פחות אינדוקס, פחות תנועה, פחות הכנסה להשקיע בשרת.
מה אני בודק קודם כל?
Time To First Byte (TTFB). אם זה מעל 600ms בממוצע, יש בעיה. שואף ל-200-400ms. אחר כך, יציבות: כמה אחוז מהבקשות חוזרות עם 200 OK? צריך להיות מעל 98%. ולבסוף, caching. אם כל בקשה של גוגלבוט מייצרת שאילתה חדשה למסד הנתונים, השרת שלכם עובד פי 10 ממה שהוא צריך.
שרשראות הפניות: הבזבוז שאף אחד לא רואה
תרחיש שאני רואה כל הזמן. האתר עבר שלוש מיגרציות בעשור האחרון. כל פעם הוסיפו 301. עכשיו דף שהיה ב-/blog/post-name מפנה ל-/posts/post-name, שמפנה ל-/articles/post-name, שמפנה ל-/blog/2024/post-name. כל הפניה כזאת היא בקשה נפרדת, ודוח Crawl Stats סופר אותן בנפרד.
גוגל אמנם עוקב אחרי שרשראות הפניות עד 5 צעדים, אבל כל צעד הוא בזבוז של תקציב סריקה, ומגדיל את הסיכוי שגוגל פשוט יפסיק באמצע.
קידום אתרים בלחיצת כפתור במערכת שלנו מזהה אוטומטית קישורים פנימיים שמובילים להפניות ומציע תיקון. זה חוסך שעות של עבודה ידנית ומונע בזבוז מתמשך של תקציב סריקה.
אילו KPI להציג כשרוצים להוכיח שיפור ב-Crawl Budget?
אם אתם מנהלים את ה-SEO בארגון, אתם צריכים מספרים לטובת ההנהלה. "שיפרנו את תקציב הסריקה" זה לא KPI. הנה מה שכן:
המספרים האלה לא משתפרים בשבוע. תנו לזה חודש-חודשיים אחרי אופטימיזציה רצינית. ואם הם כן השתפרו, יש סיכוי טוב שתראו גם עליות בדירוגים תוך 3-4 חודשים.
האם canonical חוסך Crawl Budget? (לא ישירות)
שאלה שאני מקבל הרבה. התשובה: canonical הוא רמז, לא הוראה. הוא לא חוסם סריקה. גוגל עדיין יסרוק את הדף שיש לו canonical, אבל הוא יבין שזו לא הגרסה הראשית, ובמשך הזמן יקטין את תדירות הסריקה שלו.
אז חיסכון? כן, אבל עקיף ואיטי. אם אתם רוצים לחסוך תקציב סריקה מהר, השתמשו ב-Disallow. אם אתם רוצים לאחד איתותי דירוג בין כפילויות, השתמשו ב-canonical. שני הכלים, מטרות שונות.
אתר חדש: מתי להתחיל לחשוב על Crawl Budget?
אם אתם עכשיו משיקים אתר, יש לכם הזדמנות זהב. במקום לתקן בעיות אחרי שצברתם 50,000 URL מיותרים, אתם יכולים למנוע אותן מהיום הראשון. הנה הצ'ק-ליסט שאני נותן לכל לקוח חדש:
מבנה URL נקי. בלי פרמטרים שאפשר להחליף ב-paths נקיים. /products/red-shoes ולא /products?color=red&type=shoes.
robots.txt מוכן מראש. חסימה של תוצאות חיפוש פנימיות, אזורי ניהול, וכל פרמטר מעקב.
Sitemap XML רק עם דפים שצריכים להיות באינדקס. לא להכניס דפי thank-you, לא 404, לא noindex.
קישורים פנימיים מהדף הראשי לדפי המטרה. שגוגל יבין מהיום הראשון מה חשוב.
אנחנו ב-WEBS עובדים ככה מאז 2014, עם מאות לקוחות בארץ ובעולם, מארה"ב ועד שוויץ, ואני יכול להגיד לכם שהאתרים שהתחילו עם תכנון נכון חוסכים 6-12 חודשי עבודה תיקונים בהמשך הדרך.
איך מבנה הקישורים הפנימיים מנהל בפועל את תקציב הסריקה
גוגלבוט מגלה דפים דרך קישורים. נקודה. אם דף לא מקושר משום מקום באתר (orphan page), גוגל לא ידע שהוא קיים, גם אם הוא ב-sitemap. ואם דף מקושר רק מעמוד אחד עמוק בארכיון, גוגל יחשוב שהוא לא חשוב.
קידום אתרים לפני כולם מתחיל אצלנו תמיד עם מיפוי מבנה הקישורים הפנימיים, כי זה הבסיס לכל השאר. בלי מבנה פנימי נכון, גוגל פשוט לא מגיע לדפים שחשובים לכם.
סיכום: שלושת הצעדים שאני מבצע בכל פרויקט Crawl Budget
שלב 1: מיפוי. ניתוח לוגי שרת + Crawl Stats. הבנה איפה מבוזבז התקציב. זה שלב האבחון — בלעדיו כל פעולה היא ניחוש.
שלב 2: ניקוי. robots.txt, canonical, הסרת שרשראות הפניות, סגירת חיפוש פנימי לאינדוקס. ביצוע נקודתי לפי ממצאי שלב 1.
שלב 3: ניטור. מעקב חודשי אחרי המדדים. כל שינוי במבנה האתר — תוסף, מיגרציה, עדכון תבנית — מחזיר אותנו לשלב 1.
זה לא פרויקט חד פעמי. זו עבודה שוטפת. אנחנו ב-WEBS עובדים בלי התחייבות חודשית, אתם איתנו כל עוד אתם מרוצים, וללא אותיות קטנות. מערכת WEBFORCE מנטרת את המדדים האלה אוטומטית ושולחת התראות כשמשהו משתבש, כך שאני לא צריך לחכות לדוח חודשי כדי לגלות שגוגל הפסיק לסרוק חצי מהאתר.
שאלות נפוצות שאני מקבל כל שבוע



